More than 80% of data in Organizations are in documents and forms. Digitizing this information is key to enable many transformation scenarios. Amazon Textract provides a faster, cheaper and more reliable way to digitize this unstructured data .
One of the stumbling blocks to enabling digital in a legacy enterprise is the huge amount of data that is received and exchanged as traditional documents and forms.
So far the solution has been to write custom code or use one of the Optical Character Recognition (OCR) tools.

Traditional OCR
OCR enables you to convert different types of documents – scanned documents, PDF files or even images captured by a digital camera into editable text. Here is how the popular ABBYY FineReader OCR works:
First, the program analyzes the structure of document image. It divides the page into elements such as blocks of texts, tables, images, etc. The lines are divided into words and then – into characters. Once the characters have been singled out, the program compares them with a set of pattern images. It advances numerous hypotheses about what this character is. Basing on these hypotheses the program analyzes different variants of breaking of lines into words and words into characters. After processing huge number of such probabilistic hypotheses, the program finally takes the decision, presenting you the recognized text.
The OCR technology is designed to recognize printed text in images and scanned documents. The industry came up with an extended technology called Intelligent Character Recognition (ICR)to read hand printed characters. For ICR, the characters have to be written in a machine-readable form.
Limitations of OCR
As you may have inferred, there are many limitations to both OCR and ICR though they have improved over time.
- The accuracy of the tool is not 100%. Most tools in my view are between 75 to 90% accurate.
- Limited document types can be processed. OCR or ICR works best with good quality documents that have formats ideal for OCR – what they are programmed for. It is error prone for the rest.
- The output is a bunch of words that you need to make sense of.
So, when we are looking to automate workflows that involve documents and forms, there are many exception scenarios. We are forced to introduce a manual intervention to ensure accuracy for further processing.
Applying Intelligence
With the success of Deep learning (AI/ML) technologies, people have been looking to apply these technologies to improve OCR. It uses the advances in AI to understand and classify the text better.

One example I have seen is the IQ bot from Automation Anywhere. It uses computer vision to extract and AI to learn what fields are where (eg. Invoice or purchase number) to provide more reliable results.
IQ Bot allows business users to create software bots that leverage AI and machine learning to extract unstructured data from documents, without the help of data scientists or programmers. … Built-in computer vision accurately extracts unstructured data from documents for manual processes such as invoices, purchase orders, financial statements and more.
I personally know that many other companies that claim to use AI to read unstructured documents better. Amazon though has an interesting proposition with Textract.
Amazon Textract
Amazon Textract builds on these developments and seems to be using their superior ML prowess to provide an improved OCR as a service. With Textract, Amazon claims that you can instantly “read” virtually any type of document to accurately extract text and data without the need for any manual effort or custom code
Textract uses Machine learning to understand common data types like Social Security numbers, dates of birth, addresses etc. and interprets them correctly wherever they are on a page. This is similar to what solutions like IQ bot are doing but with Amazon, the possibilities expand.
Why is Textract interesting?
There were smartphones before iPhone but Apple was uniquely positioned to bring the devices that resonated with the masses. Amazon seems to be in a unique position to bring the digitization solution that would be useful for the enterprises.
Here is why I think AWS could do this better:
Easy – Consume as a service
Amazon has been simplifying access to services enabling people to provide amazing services. Textract is no different and opens up possibilities for Entrepreneurs to go solve business problems that include unstructured data.
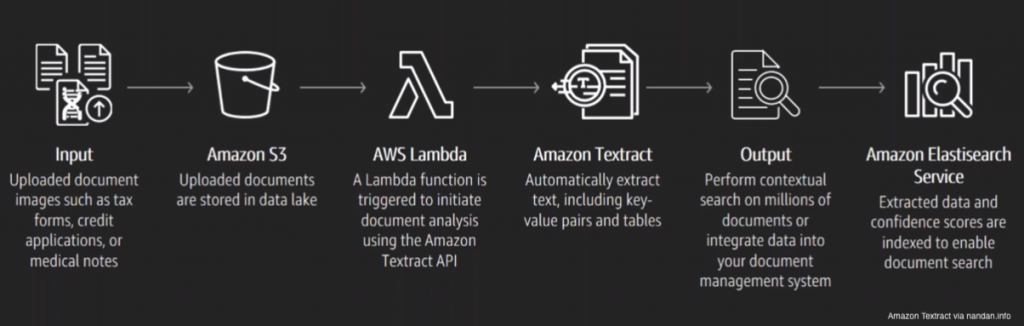
Textract being part of the AWS ecosystem, it is easier to consume and integrate. You can automate the workflow with AWS- drop the PDF in S3, trigger a Lambda function to split the files, use more Lambda functions to invoke Textract and then trigger a Lambda function to process everything.
Cheaper – 1.5c for 1000 documents
Amazon’s strategy has always been to make products and services to scale with them being the first and best customer. Here again, the biggest customer for this service is probably Amazon – Kindle books, Warehouse documents, Mechanical Turk.
With Amazon as the first customer, they can provide the service cheap, gain traction and reduce costs further as they gain traction with the service.
Better – More data means better product
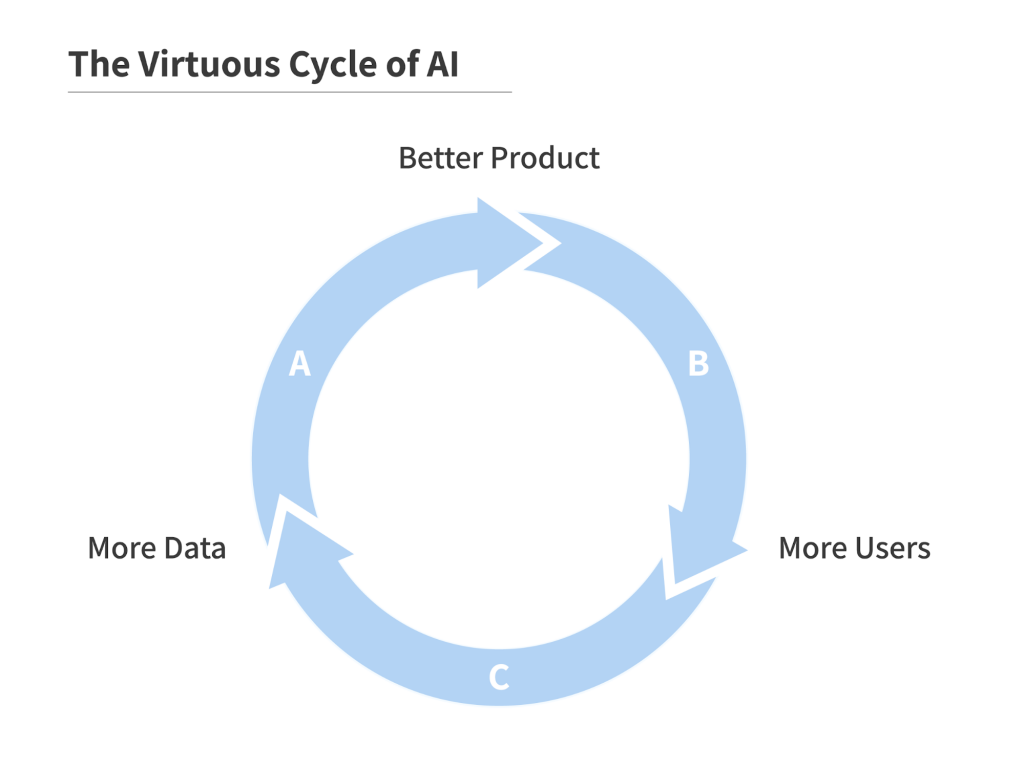 Data is a key asset for AI/ML – more data leads to the Virtuous cycle of AI that Andrew NG talks about. With the frictionless Textract service, Amazon can build a huge data set of documents and forms of various type. This is assuming many customers jump on this platform
Data is a key asset for AI/ML – more data leads to the Virtuous cycle of AI that Andrew NG talks about. With the frictionless Textract service, Amazon can build a huge data set of documents and forms of various type. This is assuming many customers jump on this platform
This data helps Amazon build a more accurate OCR engine, which in turn helps them acquire more users, which then results in even more user data. The resulting positive feedback loop will be hard for others to break into.
Probable Pitfalls
While this sounds great, there are some challenges for Amazon and Textract to overcome.
As per their FAQ:
Amazon Textract may store and use document and image inputs processed by the service solely to provide and maintain the service and to improve and develop the quality of Amazon Textract
As we saw above, this is needed for machine learning and to improve the accuracy. This may be a non-starter for many enterprises though. It will be interesting to see if this does actually trip this service.
As I said, this is not a new solution entirely though Amazon seems to have its advantages. While the service does look promising, we have to actually see how accurate the recognition itself is and how easy it is to use. As I write this, It is currently in preview.
Conclusion
We still need to understand the accuracy and how Amazon handles the various tricky aspects. I think Amazon does have a good chance to co-opt the innovations so far and build on it.
If we can figure out a way to digitize 80% of world data and structure them for algorithms, we can use the stream for more insights. The possibilities are endless.